Golang读取文件和处理超大文件
在日常编码中,常常也会遇到如何读取文件,其实读取文件看是简单,但是如果文件是一个特别大的文件,那么如何办呢?本文主要讲解下如何读取文件?
- 整个文件读取
- 适用场景:文件较小
- 按照每行读取
- 适用场景:如果是大文件,文件内容有严格的分行,可以使用分行读取
- 按照块读取
- 使用场景:超大文件
文件准备
$ ll -h
total 462M
-rw-r--r-- 1 zhj 197121 14M 6月 5 13:55 file_1.log
-rw-r--r-- 1 zhj 197121 414M 6月 5 13:54 file_2.log
整文件读取
示例1
常规读取文件操作
package main
import (
"fmt"
"io/ioutil"
"log"
"os"
"time"
)
func main() {
file1 := "./file_1.log"
file2 := "./file_2.log"
readFileBuff(file1)
readFileBuff(file2)
}
//读取文件,常规流程
func readFileBuff(filename string) (content []byte) {
startTime := time.Now()
//打开文件
fileHandler, err := os.Open(filename)
if err != nil {
log.Println(err.Error())
return
}
//关闭文件
defer fileHandler.Close()
//获取当前文件的信息
fileInfo, err := fileHandler.Stat()
if err != nil {
log.Println(err.Error())
return
}
//初始化切片的长度
content = make([]byte, fileInfo.Size())
//读取文件内容到content中
n, err := fileHandler.Read(content)
if err != nil {
log.Println(err.Error())
return
}
fmt.Println("读取的内容长度:", n)
fmt.Println("运行时间:", time.Now().Sub(startTime))
return content
}
运行结果:
$ go run main.go
读取的内容长度: 13816352
运行时间: 8.9166ms
读取的内容长度: 433550208
运行时间: 258.3091ms
上面读取文件是我们一个比较常规的操作,但是实际在golang中,已经有包帮我们处理了这个读取,io/ioutil包就是干了这件事,下面示例2就是采用该包读取
示例2
package main
import (
"fmt"
"io/ioutil"
"log"
"time"
)
func main() {
file1 := "./file_1.mp4" //14M
file2 := "./file_2.mp4" //414M
readFile(file1)
readFile(file2)
}
//读取文件
func readFile(filename string) (content []byte) {
startTime := time.Now()
content, err := ioutil.ReadFile(filename)
if err != nil {
log.Println(err.Error())
}
fmt.Println("读取的内容长度:", len(content))
fmt.Println("运行时间:", time.Now().Sub(startTime))
return
}
运行结果:
$ go run main.go
读取的内容长度: 13816352
运行时间: 7.976ms
读取的内容长度: 433550208
运行时间: 291.2078ms
是不是比示例1简单了很多,可以去看readFile的实现,内部的大致流程就是按照示例1去实现的。
分片读取
当一个文件是非常大,如20G的日志文件,我们按照上面的整个文件读取,其实是不现实的,可能内存都没有这么大,那么我们就要考虑分段读取。
分段读取的思路:
- 设置一个容量的切片
- 每次都读取固定长度的内容到切片中
- 直到文件内容读取完为止
package main
import (
"fmt"
"io"
"io/ioutil"
"log"
"os"
"time"
)
func main() {
file1 := "./file_1.log"
file2 := "./file_2.log"
readBlock(file1)
readBlock(file2)
}
//分片读取
func readBlock(filename string) (content []byte) {
startTime := time.Now()
//打开文件
fileHandler, err := os.Open(filename)
if err != nil {
log.Println(err.Error())
return
}
//关闭文件
defer fileHandler.Close()
buffer := make([]byte, 1024)
for {
n, err := fileHandler.Read(buffer)
if err != nil && err != io.EOF {
log.Println(err.Error())
}
//读取完成
if n == 0 {
break
}
content = append(content, buffer[:n]...)
}
fmt.Println("读取的内容长度:", len(content))
fmt.Println("运行时间:", time.Now().Sub(startTime))
return
}
运行结果:
$ go run main.go
读取的内容长度: 13816352
运行时间: 83.8145ms
读取的内容长度: 433550208
运行时间: 2.5322629s
逐行读取
逐行读取适合大文件,逐行读取要求文件里面的内容一定是分行存储的,并且每行的内容不能过大。
方式一:
package main
import (
"bufio"
"fmt"
"io"
"io/ioutil"
"log"
"os"
"time"
)
func main() {
file1 := "./file_1.log"
file2 := "./file_2.log"
readLine(file1)
readLine(file2)
}
func readLine(filename string) (content []byte) {
startTime := time.Now()
//打开文件
fileHandler, err := os.Open(filename)
if err != nil {
log.Println(err.Error())
return
}
//关闭文件
defer fileHandler.Close()
lineReader := bufio.NewReader(fileHandler)
for {
line, _, err := lineReader.ReadLine()
if err != nil && err == io.EOF {
break
}
content = append(content, line...)
}
fmt.Println("读取的内容长度:", len(content))
fmt.Println("运行时间:", time.Now().Sub(startTime))
return
}
运行结果:
$ go run main.go
读取的内容长度: 13755104
运行时间: 57.8427ms
读取的内容长度: 431320344
运行时间: 1.7922053s
方法二:
package main
import (
"bufio"
"fmt"
"io"
"io/ioutil"
"log"
"os"
"time"
)
func main() {
file1 := "./file_1.log"
file2 := "./file_2.log"
readScanner(file1)
readScanner(file2)
}
func readScanner(filename string) (content []byte) {
startTime := time.Now()
//打开文件
fileHandler, err := os.Open(filename)
if err != nil {
log.Println(err.Error())
return
}
//关闭文件
defer fileHandler.Close()
lineScanner := bufio.NewScanner(fileHandler)
for lineScanner.Scan() {
content = append(content, lineScanner.Bytes()...)
}
fmt.Println("读取的内容长度:", len(content))
fmt.Println("运行时间:", time.Now().Sub(startTime))
return
}
执行结果:
$ go run main.go
读取的内容长度: 13755104
运行时间: 51.8617ms
读取的内容长度: 431320344
运行时间: 1.623657s
总结:
- 从以上三种读取文件的方式可以看出,整个文件读取的效率是非常高的,但是这种方式只适用于小文件,大文件这样读取可能造成内存溢出
- 如果文件内容特别大,最好使用分片读取和逐行读取,但是逐行读取的文件要注意每行的内容不能太大,否则也会出现问题
- 二进制文件适合使用整个文件读取和分片读取
- 对文件内容需要处理最好选用分片读取和逐行读取
热门标签
每日一句
-
最深最平和的快乐,就是静观天地与人世,慢慢品味出它的美与和谐。
——三毛
今日排行
- mac git用户名和密码修改
 在Mac电脑中,如何对Git的用户名和密码进行修改呢?起初不懂Mac,所以整了很久,本文将记录如何对这个进行操作,以便后期使用。
在Mac电脑中,如何对Git的用户名和密码进行修改呢?起初不懂Mac,所以整了很久,本文将记录如何对这个进行操作,以便后期使用。 - 速查表
 速查表是自己整理了一份在工作中常用的一些资料,包含了自己在日常开发中需要常常用到的相关技术。可以给读者进行参考。
速查表是自己整理了一份在工作中常用的一些资料,包含了自己在日常开发中需要常常用到的相关技术。可以给读者进行参考。 - 微信小程序支持Markdown的解析库Towxml和搭建公式流程图渲染服务
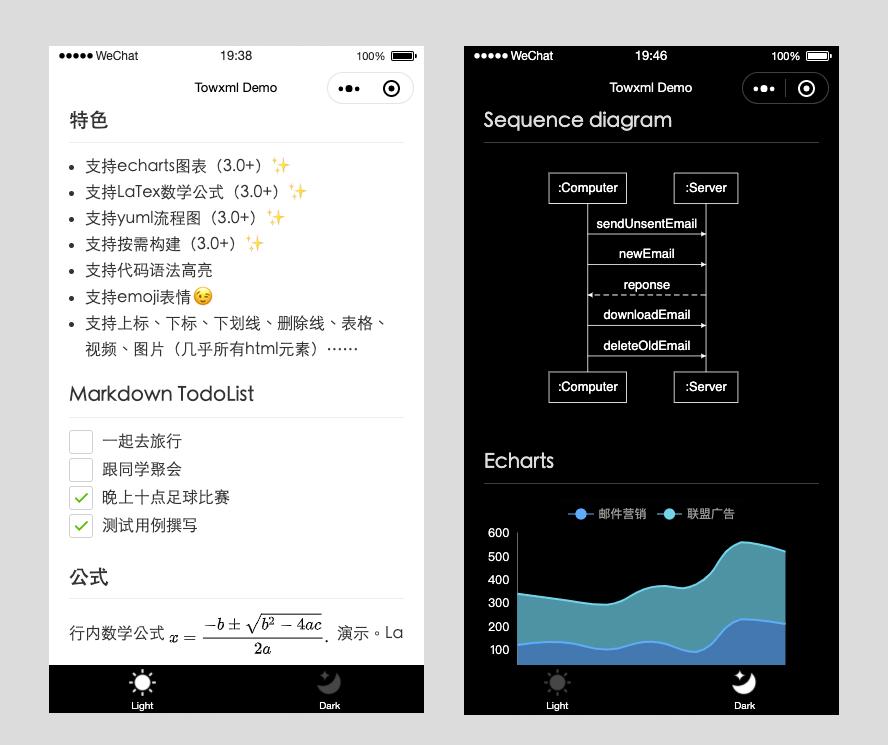 Towxml 是一个让小程序(微信/QQ)可以解析Markdown、HTML的解析库。能够使小程序完美解析Markdown内容。
Towxml 是一个让小程序(微信/QQ)可以解析Markdown、HTML的解析库。能够使小程序完美解析Markdown内容。 - yarn、npm配置阿里云国内镜像(新镜像)
 nodejs中使用npm和yarn,使用最新阿里云镜像 aliyun mirror,网上很多还是文章用的是下面这个地址~~yarn config set registry https://registry.npm.taobao.org~~
nodejs中使用npm和yarn,使用最新阿里云镜像 aliyun mirror,网上很多还是文章用的是下面这个地址~~yarn config set registry https://registry.npm.taobao.org~~ - 推荐一款Markdown编辑器
 Editor.md 是一个可嵌入的开源 Markdown 在线编辑器组件,你可以很方便用在浏览器、NW.js(Node-webkit)等地方,基于CodeMirror、jQuery 和 Marked 构建。
Editor.md 是一个可嵌入的开源 Markdown 在线编辑器组件,你可以很方便用在浏览器、NW.js(Node-webkit)等地方,基于CodeMirror、jQuery 和 Marked 构建。
点击排行
- VSCode插件 - 快速生成表格并格式化
 快速生成表格
快速生成表格 - Electron页面跳转、浏览器打开链接和打开新窗口
 Electron页面跳转、浏览器打开链接和打开新窗口
Electron页面跳转、浏览器打开链接和打开新窗口 - Electron打包错误“Error: Application entry file ..”解决方案
打包出现如下错误:Error: Application entry file "dist\electron\main.js" in the "D:\gui\demo2\build\win-unpacked\resources\app.asar" does not exist. Seems like a wrong configuration.
- Git保存和清除用户名、密码
 在使用Git的过程中,不想每次都输入用户名和密码去拉取代码,所以就需要保存这些信息,那么既然有保存了,就必须有清除功能。
在使用Git的过程中,不想每次都输入用户名和密码去拉取代码,所以就需要保存这些信息,那么既然有保存了,就必须有清除功能。 - mac git用户名和密码修改
在Mac电脑中,如何对Git的用户名和密码进行修改呢?起初不懂Mac,所以整了很久,本文将记录如何对这个进行操作,以便后期使用。
- Docker编译出现:temporary error (try again later)
 Docker编译镜像出现:fetch http://dl-cdn.alpinelinux.org/alpine/v3.12/main/x86_64/APKINDEX.tar.gz
ERROR: http://dl-cdn.alpinelinux.org/alpine/v3.12/main: temporary error (try again later)
WARNING: Ignoring APKINDEX.2c4ac24e.tar.gz: No such file or directory问题
Docker编译镜像出现:fetch http://dl-cdn.alpinelinux.org/alpine/v3.12/main/x86_64/APKINDEX.tar.gz
ERROR: http://dl-cdn.alpinelinux.org/alpine/v3.12/main: temporary error (try again later)
WARNING: Ignoring APKINDEX.2c4ac24e.tar.gz: No such file or directory问题